Répartition des phrases selon leur longueur :
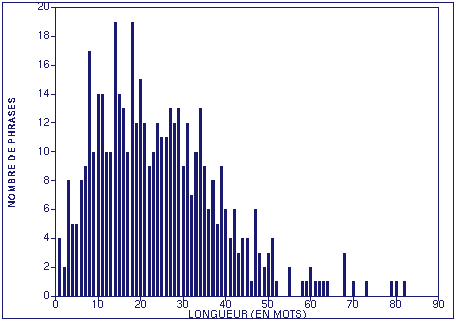
| Nb de phrases | 474 |
| Longueur maximale | 82 |
| Longueur moyenne | 24,43 |
| Nb de mots | 11583 |
Les fichiers accessibles en lignes étant régulièrement remis à jour en fonction de l'évolution de l'analyseur, des décalages peuvent être constatés entre la version courante et l'évaluation présentée ici.
À titre d'information, cette évaluation est datée d'avril 1997.
L'évaluation de l'analyseur a été menée sur une série d'articles du journal "Le Monde" ; corpus qui n'a pas servi à l'évaluation de la base de règles. 24 extraits d'articles relevant de divers domaines (tels que la politique, l'économie, la mode, la haute-technologie, le vie de tous les jours...) ont été utilisés. Au total, 474 phrases constituent ce corpus. La définition de phrase choisie pour cette évaluation correspond à la définition standard bien que les séparateurs ";" et ":" aient été ajoutés. La figure 1 représente la répartition des phrases en fonction de leur longueur.
Répartition des phrases selon leur longueur :
| Nb de phrases | 474 |
| Longueur maximale | 82 |
| Longueur moyenne | 24,43 |
| Nb de mots | 11583 |
Le corpus a été annoté manuellement par une linguiste de l'action GRACE (action d'évaluation des étiqueteurs grammaticaux du français) à l'aide du jeu d'étiquettes standard proposé dans les projets MULTEXT et EAGLES. Ce jeu d'étiquettes comporte 11 catégories principales. Chacune de ces catégories est complétée par un maximun de 6 attributs pouvant prendre jusqu'à 8 valeurs distinctes.
Pour les besoins de l'évaluation, une fonction de conversion a été écrite afin de transféré notre jeu d'étiquettes dans celui utilisé par l'action GRACE. La segmentation en unités est très fine (les apostrophes sont des unités) et fait apparaître 12691 jetons.
Dans le protocole utilisé pour l'évaluation, l'étiquette est (1) correcte si l'analyseur a assigné une seule étiquette avec une valeur correcte dans tous les champs qui la composent. (2) ambigue si l'analyseur a assigné plusieurs étiquettes ou bien si l'un des champs d'une étiquette possède plusieurs valeurs, (3) incorrecte si l'étiquette correcte ne peut être trouvée dans les propositions de l'analyseur.
Deux évaluations ont été menées. Dans la première, l'étiquette n'est composée que d'un seul champ : La catégorie principale. Dans la seconde, l'étiquette est composée de la catégorie principale et de ses attributs. Les résultats présentés ne sont pas les résultats officiels de l'action GRACE car l'épreuve officielle n'a pas encore eu lieu.
| Évaluation | tokens | corrects | ambigus | incorrects | % corrects |
|---|---|---|---|---|---|
| Étiquette complète | 12691 | 11502 | 516 | 673 | 90,63% |
| Étiquette principale | 12691 | 12524 | 0 | 167 | 98,68% |
Bien que l'analyseur calcule la plupart des relations, l'évaluation que nous vous proposons se restreint à la relation sujet-verbe pour la simple raison et bonne raison qu'aucune banque de corpus étiquetés n'est actuellement disponible pour le français. Le travail doit donc être effectué manuellement. Pour évaluer les autres relations, il vous est possible d'utiliser le visualiseur afin d'apprécier leur qualité.
Le corpus comporte 738 relations sujet-verbe sur lesquels porte l'évaluation. La répartition du nombre de relations sujet-verbe par phrase est la suivante :
Nombre de relations sujet-verbe par phrase :
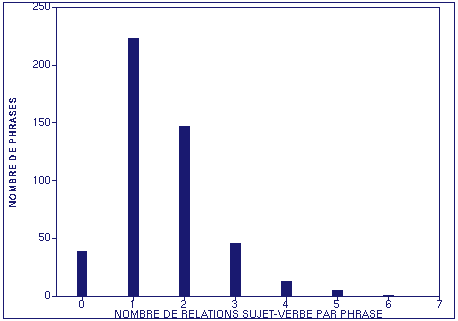
Afin de préciser l'évaluation, nous avons distingué 4 types de relations sujet-verbe en fonction de la nature du sujet : (1) Syntagme nominal, (2) Syntagme verbal infinitif, (3) Pronom relatif, (4) Pronom personnel.
| Nature du sujet | Nombre |
|---|---|
| Syntagme nominal | 458 |
| Syntagme verbal infinitif | 2 |
| Pronom relatif | 85 |
| Pronom personnel | 193 |
| Total | 738 |
Une autre mesure intéressante est la distance entre le verbe et son sujet. Cette mesure n'est présentée que pour un sujet nominal, cas où l'on trouve des relations à longue distance. On notera cependant que les pronoms personnels et relatifs peuvent être des sujets lointains en situation d'énumération de verbes et d'insertion de groupe prépositionnel. La figure suivante montre que la plus longue relation entre un sujet et son verbe est de 45 mots dans une relation standard et de 8 mots dans une relation sujet-verbe inversée.
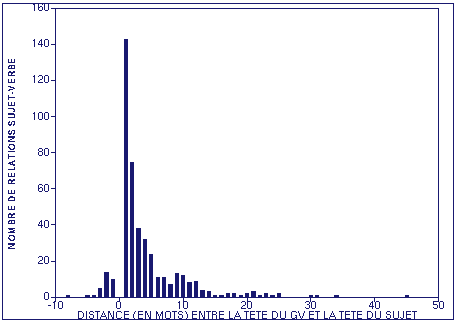
La fonction d'évaluation est fondée sur le principe suivant : chaque verbe doit dépendre d'au plus un sujet. De ce point de départ, 3 cas se présentent : le résultat est correct si le verbe dépend du bon sujet, incorrect dans le cas contraire, silence si aucun sujet n'a été trouvé mais un était attendu.
Dans le cas de coordination de sujets, une relation correcte est comptée pour chaque verbe dépendant de cette coordination et relié uniquement à la tête de la coordination (i.e., le premier sujet). Dans le cas de coordination de verbes, une relation correcte est comptée pour chaque verbe relié au sujet attendu, une relation incorrecte est comptée pour chaque verbe non relié au sujet attendu.
Les résultats sont présentés ci-dessous. Precision correspond au nombre de relations correctes par rapport au nombre de relations trouvées. Recall correspond au nombre de relations correctes par rapport au nombre de relations total du corpus.
| Nature du sujet | number | correct | incorrect | silence | précision | recall |
|---|---|---|---|---|---|---|
| Syntagme Nominal | 458 | 418 | 26 | 14 | 94,14% | 91,27% |
| Syntagme Infinitf | 2 | 2 | 0 | 0 | 100.00% | 100.00% |
| Pronom Relatif | 85 | 85 | 0 | 0 | 100,00% | 100,00% |
| Pronom Personnel | 193 | 191 | 0 | 2 | 100,00% | 98,96% |
| Total | 738 | 694 | 26 | 16 | 96,39% | 94,04% |
Ces résultats sont encourageants et peuvent bien sûr être améliorés puisque ceux sont les premiers menés sur un aussi gros corpus inconnu (738 relations). Les 42 silences et relations incorrectes peut être classées en 5 catégories : (1) implémentation incorrecte de la vérification d'accord, (2) syntagme non-récursif mal construit, (3) coordination non résolue, (4) sujet inversé dans un discours rapporté, (5) étiquette de syntagmes non-récursifs incorrecte. Les cas 4 et 5 demandent une étude approfondie de manière à être gérés correctement.